Основа основ – кодировка ASCII и ее современные интерпретации.
Мощный старт
На сегодняшний день кодировка ASCII представляет собой стандартом представления первых 128-значений (включая цифры и знаки препинания) английского алфавита, представленных в определенном порядке.
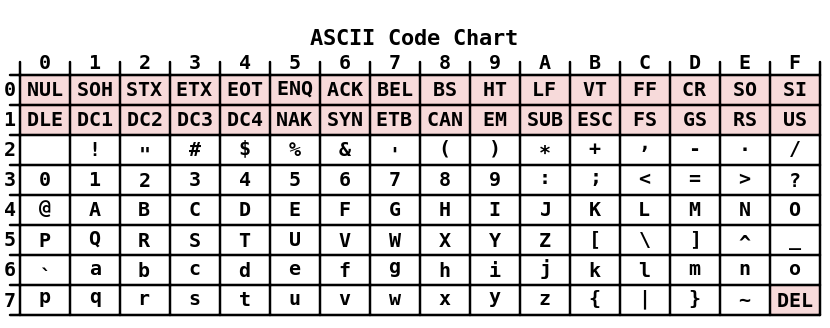
Однако, даже 1 байт позволяет закодировать в 2 раза больше значений, то есть не 128, а целых 256 разных значений. Поэтому достаточно быстро на смену базовой ASCII стали появляться более расширенные варианты этой знаменитой и популярной по сей день кодировки, в которых кодировались также символы алфавитов и, соответственно, текста различных языков, в том числе и русского.
Расширения ASCII для России
На сегодняшний день для российских пользователей приоритетными являютсякодировка Windows1251 и кодировка юникод, а также UTF 8, которые произошли от ASCII.
Собственно говоря, у кого-то может возникнуть весьма справедливый вопрос: «А зачем вообще нужны эти кодировки текстов?»
Стоит помнить, что компьютер – это всего-навсего машина, которая должна действовать четко по инструкциям. Чтобы было понятно, что нужно делать с каждым символом написанного, его представляют в виде набора векторных форм, каждый набор которых отправляет в нужное место, чтобы на экране появлялось то или иное обозначение.
За формирование векторных форм отвечают шрифты, а сам процесс кодирования зависит от операционной системы, а также используемых в ней программ. Таким образом, каждый текст по своей сути – это некоторый набор байтов, в каждом из них представлена кодировка одного написанногосимвола. А программа, занимающаяся отображением напечатанной информации на экране (это может быть браузер или текстовый процессор), разбирает код, находит подходящее отображение по его коду в таблице кодировок, преобразует в необходимую векторную форму и отображает в текстовом файле.
Кодировка CP866 и KOI8-R широко применялись до появления графической операционной системы, завоевавшей популярность во всем мире, - Windows. Теперь самой популярной кодировкой, поддерживающей русский, стала Windows1251.
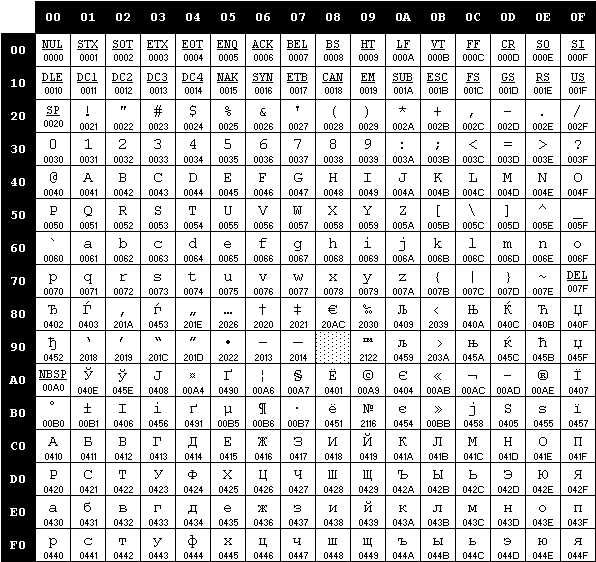
Однако, она не единственная, поэтому у производителей шрифтов для русского, используемых в программном обеспечении, периодически даже до сих пор появляются затруднения, связанные с неверным отображением символов и появлением так называемой кракозябры. Эти несуразные иероглифы являются результатом некорректного использования таблиц кодировок, то есть при кодировании и декодировании использовались разные таблицы.
Такая же ситуация имеет место и на сайтах, блогах и прочих ресурсах, где есть информация на русском и прочих иностранных символах, отличных от английских. Данная ситуация определила основную предпосылкой создания универсальной кодировки, позволяющей кодировать текст на любом языке, даже китайском, где символов значительно больше, чем 256.
Универсальные кодировки
Первой версией универсальной кодировки, разработанной в рамках консорциума Юникод, была кодировка UTF 32. Для кодирования каждого символа использовалось 32 бита. Теперь была реализована возможность кодирования огромного количества знаков, но появилась другая проблема –большинству европейских стран такое число лишних символов было совершенно не нужно. Ведь документы получались очень тяжелыми. Поэтому на смену UTF 32 пришла UTF 16, ставшая базовой для всех символов, используемых в нашей стране и не только.
Но все равно оставалось достаточно много недовольных. Например, те, кто общался только на английском языке, так как при переходе с ASCII на UTF 16 их документы все равно увеличивались в размерах, причем существенно, практически в 2 раза.
В результате появилась кодировка переменной длинны UTF 8, что позволило не увеличивать вес текста.
Кракозябры и методы борьбы с ними
Вообще, кодировка задается на странице, где создается само информационное сообщение. В результате, в начале документа формируется своеобразная метка, в которой запоминается, в прямом или обратном порядке записаны коды символов UTF16.
Если что-то было напечатано в UTF-8, то никакого маркера в начале нет, так как сама возможность записи кода символа в обратном порядке в этой кодировке отсутствует.
Поэтому, следует сохранять все, что набрано в редакторе, без маркеров (BOM), чтобы снизить вероятность появления кракозябров в документе.
Помимо правильного сохранения рекомендуется отказаться от использования стандартного редактора Windows«Блокнот», а выбрать более совершенную среду для редактирования документов сайта.
Еще одним полезным советом по борьбе с кракозябрами – прописать в шапке кода каждой страницы сайта информацию о правильной кодировке текста, чтобы ни на локальном хосте, ни на сервере не было путаницы.
Например, так
<?xml version=”1.0” encoding=”windows-1251”?>
Или так
<head>
…
<meta charset=”utf-8”>
</head>